В настоящей статье будет описано применение диаграммы последовательности как промежуточного этапа между предшествующими диаграммами, которые в большей степени служили для согласования и оптимизации бизнес-процессов, и сугубо техническими, описывающими построение программного продукта.
На мой взгляд, диаграмма последовательности является самой недооцененной диаграммой из всего набора диаграмм UML. В основном, разработчики используют ее для моделирования сетевых или меж платформенных соединений, то есть внешних по отношению к разрабатываемому продукту, однако область ее применения значительно шире. В бизнесе, подобные используются для описания последовательности действий, движения товаров, информации и документов, то есть хорошо иллюстрируют документооборот компаний. В этой статье мы рассмотрим как с помощью такой диаграммы можно выстраивать внутреннюю структуру приложения.
В прошлых статьях, мы спроектировали поведение программы при работе с книгой. По очевидным причинам, в статьях описывается проектирование только небольшого участка запланированного программного продукта. Каждый читатель, опираясь на последовательное описание, самостоятельно, может дополнить проект из желания потренироваться или просто из спортивного интереса. В любом случае, лучше прочитать все статьи цикла последовательно, даже если вы начали чтение именно с этой статьи. Цикл изначально задумывался и писался как последовательное изложение принимаемых решений, от идеи, до программного кода.
Текущая статья будет содержать много технических рассуждений, как основу для принятия конкретных решений. В общем, эта статья иллюстрирует не сколько построение диаграммы, сколько приемы решения технических вопросов. Впрочем как и другие статьи цикла.
Переходя непосредственно к постановке вопросов, определим наши исходные позиции. К данному моменту уже есть общее понимание интерфейса. UX/UI дизайнер создал общую концепцию интерфейса, согласовал ее с заказчиком. Да. Возможно она будет видоизменяться, но мы сразу примем несколько решений которые, минимизируют потенциальные проблемы.
В этом проекте нет UX/UI дизайнера, да и сам я далек от этой темы, поэтому опишу собственное, представление интерфейса. При чтении книги хотелось бы видеть бесконечную ленту, которую можно было бы прокручивать от начала к концу книги. Слева, сворачиваемая панель в развернутом положении показывает содержание книги, а в свернутом отображает маркер положение активного окна в объеме книги, аналогично отображению полосы прокрутки. Справа, подобная панель, которая в раскрытом положении отображает комментарии для активного окна, а в свернутом, места в тексте где выделены цитаты и оставлены комментарии. Разными цветами.
Цитаты создаются путем выделения блока текста, при этом неважно как это делается, указателем мыши или через прикосновение к экрану.
Все цитаты выделяются цветом в тексте. Для комментирования необходимо выделить блок и в левом окне ввести текст. Комментарии не выделяются, а добавляют специальный знак к тексту.
Стараясь уложиться в рамки статьи, описывать работу с панелями я не буду, тем более если вы интересуетесь проектированием, предположить их реализацию не сложно, сосредоточимся на представлении книги.
В первую очередь, стоит учесть, что по мере разработки понимание визуального представления может измениться. Заказчик или мы сами в ходе тестирования можем принять решение об изменении интерфейса, следовательно его разработку необходимо отделить от основного решения. Это легко достигается путем разделения на преставление (View), код который будет генерировать визуальную часть. Код который реализует бизнес-логику, модель (Model), и код который осуществляет управление этими двумя этими частями, контроллер (Control). Все вместе не что иное, как паттерн MVC.
Корректно разделить представление и модель поможет диаграмма последовательности. Начнем с преставления (View). Сложность отображения книг заключается в их объеме, если подготовить к отображению весть текст сразу, он будет занимать слишком много оперативной памяти и замедлять работу. Если отображать только актуальный экран, необходимо где-то хранить ссылку на актуальную позицию и все равно получить весь текст, чтобы найти эту позицию. Именно так работают программы работы с текстом. Microsoft Notepad не загружает большие файлы потому, что не может корректно работать с памятью. Сайты, с возможностью чтения книг, отображают текст в виде страниц. Мобильные приложения для чтения, также используют работу с файлами, выполняя их пред загрузку. Текстовые процессоры типа Microsoft Word не загружают файл целиком, только актуальный фрагмент, но все равно работают с файлом.
Мы же попробуем разработать собственный функционал, который будет показывать текст книги как «бесконечную ленту», по аналогии с лентами социальных сетей. Начнем с понятия активное окно. Будем считать, что активное окно состоит из некоторого количества единиц текста, при этом за единицу текста примем абзац. По многим соображениям. В первую очередь, абзац всегда имеет прямоугольную форму, высоту и ширину которого всегда можно рассчитать, при этом большинство инструментов вывода текста могут делать это самостоятельно.
Следовательно, представление должно состоять из очереди фрагментов активным из которых является один из средних.
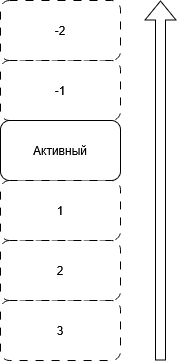
Получаем достаточное количество параметров, с помощью которых можно управлять поведением отображения. Количество единиц текста во фрагменте, длинна очереди, количество фрагментов до и после активного окна. Все это пригодится при тестировании. К тому же, сделает задел на будущее. Всегда можно будет расширить функционал, где каждый пользователь сможет самостоятельно настраивать ленту под себя, или еще интереснее, применить искусственный интеллект который будет подстраиваться, ориентируясь на предыдущее поведение пользователя.
Когда со сложностями представления разобрались, можно перейти к построению диаграммы последовательности.
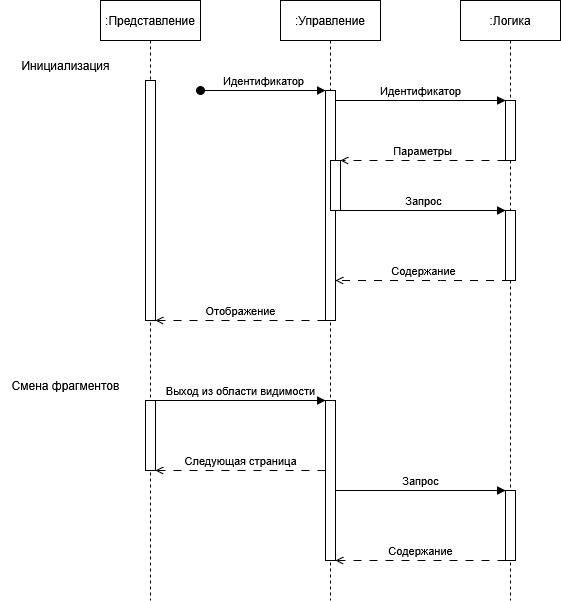
Фактически здесь не одна а две диаграммы, и формально так делать не нужно, но так легче сравнивать да и место в статье сэкономил. По своему содержанию, диаграммы просты. Первая показывает момент инициализации начального состояния, а вторая добавление страниц в очередь, при прокрутке ленты.
На момент начала работы с книгой, мы уже имеем идентификатор пользователя, поэтому из слоя бизнес-логики мы можем получить параметры для организации отображения текста, в актуальном состоянии. Хочу обратить ваше внимание, что на данном этапе проектировщик не должен опускаться в детали. Мы знаем, что набор параметров существует, и этого нам достаточно. Преждевременная детализация всегда, делает все сложнее и приводит к ошибкам.
Какие-то из этих параметров указывают, какую книгу мы хотим открыть и где мы остановились. Зная это, мы отправляем запрос на содержимое из книги, получаем необходимый текст. Далее, в слое управления, транслируем содержание в удобный для отображения вид, и отправляем в слой представления.
Здесь потребуется небольшое пояснение. Очень редко, да почти никогда, формат хранения данных не совпадает с форматом в котором они используются. Появляется соблазн применить единый формат для обоих случаев, и если разработчик поступает именно таким образом любое внесение изменений в данные, приводят к значительным изменениям в архитектуре. Поэтому более очевидным и разумным является преобразование данных непосредственно перед их использованием.
В нашем случае, используя связку паттерна MVC и принципа SOLID, инверсия зависимостей (Dependency Inversion Principle, DIP), получаем гибкую структуру нашего программного продукта.
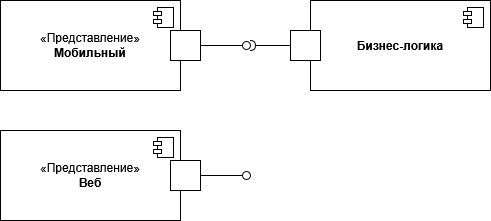
Такой подход с легкостью, при необходимости, позволит заменить один компонент на другой. В результате, в компоненте отвечающем за бизнес-логику используется удобный для обработки и хранения формат данных, а управляющий слой представления всегда может преобразовать их в необходимую для отображения форму.
Более подробно, с описанием классов, рассмотрим этот пример в одной из следующих статей, посещенной проектированию с диаграммой классов.
Мы же продолжим рассмотрение диаграммы последовательностей, её второй части. Слой представления в момент, когда фрагмент текста выходит из области видимости, сообщает об этом слою управления. Из очереди фрагментов извлекается очередной и передается представлению. В дальнейшем, слой управления запрашивает новый фрагмент для восстановления длинны очереди.
Все это происходит в синхронном режиме и конечно можно запланировать выполнение восстановления длинны очереди в асинхронном режиме.
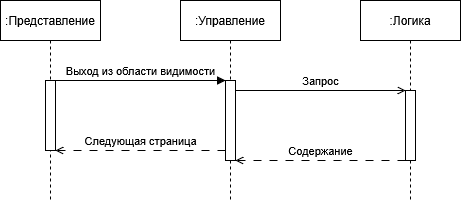
На диаграмме все это будет выглядеть великолепно, сократилось время реакции в управляющем слое. Однако давайте проведем мысленный эксперимент. Пользователь быстро просматривает ленту. Запросы на получение содержания, в слое бизнес-логики все равно выполняются последовательно, и то что мы отыграли в слое управления нивелируется в слое логики. Добавление асинхронности в слой бизнес-логики приведет к неоправданному увеличению сложности проекта, а там и проблемы со сроками и деньгами.
Здесь воспроизведена довольно часто встречающаяся ошибка. Разработчики часто хотят применить самые передовые и технологичные решения, но часто это оборачивается проблемами спроецированными в будущее.
Продолжим мысленный эксперимент. Допустим мы сразу не заметили созданного узкого места. С большой долей вероятности, эта проблема не проявится в течении некоторого времени, пока нагрузка не достигнет определенного порога. Заказчик потребует решить эту проблему. Тесты покажут, что падение производительности возникает в бизнес-логике, к тому моменту, про асинхронность в слое управления все забудут. Мы попали в ситуацию цугцванга, когда любой следующий ход только ухудшает наше положение. Для того, чтобы, проанализировать и вернуться к слою управления, необходимо много времени и высоко классные специалисты. Добавить асинхронность в бизнес-логику не реально из-за объема работ. Все упирается в производственные затраты. Из каких резервов будут оплачиваться дополнительные работы? Никто не хочет работать бесплатно. В результате, будет сделана программная заплатка, постепенное накопление которых потребует перепроектирования кода (англ. refactoring).
От ошибок, никто из нас не застрахован. Однако не стоит множить их количество неоправданным усложнением проекта. Простые решения всегда надежнее.
Закончим наш эксперимент с асинхронностью, это не значит, что она плоха сама по себе, мы можем поступить намного проще. Желание быстро пролистать книгу не является естественным для чтения, это скорее привычка из социальных сетей. Следовательно, необходимо подсказать пользователю более оптимальное поведение. Когда пользователь начинает быстро перемещать ленту, можно каким-то образом подсветить возможность перемещения через оглавление. Тем самым мотивировать к изменению поведения. С таким хорошо справляются UX/UI дизайнеры, а если это не помогает использовать самые простые способы. Изменить алгоритм. Сначала увеличить длину очереди, далее попробовать использовать динамический размер и так далее, постепенно усложняя решение. Хотя по опыту, уже на второй итерации проблема решается.
Теперь разберем функционал для создания цитат. По завершению выделения цитаты пользователем, данные о выделении, в нашем случае начальная и конечная позиция, должны быть обработаны. Ведь за единицу мы приняли абзац, а пользователь может выделить и одно слово, и несколько абзацев и не факт, что целиком.
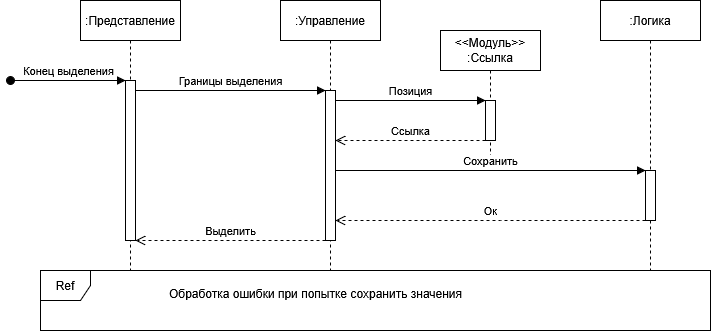
Когда границы выделения сформированы, значения передаются для формирования ссылок. Стоит напомнить, что позиции границ будут определены в формате удобном для представления, однако храниться они будут в формате удобном для обработки и хранения данных. Следовательно необходим модуль выполняющий трансляцию из одного формата в другой.
Остановимся на модуле отдельно. Каждая позиция должна содержать в себе множество информации, давайте перечислим, чтобы понимать уровень сложности задачи. Идентификатор книги (ISBN), наименование, авторы, издательство, год публикации, часть, глава, абзац, позиция символа от начала абзаца, дата изменения, конспект, автор конспекта и др. Такая связь пригодиться во многих местах, каталогизация, поиск, отчеты, технический анализ. Следовательно, нам необходимо контролировать целостность данных на всем протяжении, от представления, через бизнес-логику, до системы хранения данных.
Самым простым методом добиться этого, свести функционал отвечающий за целостность в один модуль. Ведь если упустить этот момент, функционал работы с ссылками будет размазан по всему программному продукту и попытки внести изменения приведут к значительным переделкам, а по прошествии некоторого времени пост проектного обслуживания к разрывам связей.
Очевидно, что не вся эта информация должна быть представлена явно, в одном наборе данных. Некоторую её часть можно определить как условно постоянную, например информацию о книге, и обращаться к ней по необходимости, подгружая её. Другая часть может быть оперативно изменена и должна храниться всегда в актуальном состоянии.
В нашей библиотеке, в рамках текущего примера, такой информации нет, а вот если будем автоматизировать, например складской учет, актуальность остатков на складах, при быстрых продажах, большая задача.
Теперь, когда с назначением модуля мы разобрались, можно перейти к сохранению. Мы понимаем, что ссылка это набор данных и перед тем как сообщить о его корректном сохранении, необходимо выполнить ряд проверок. В ходе действий по сохранению, может возникнуть множество исключительных ситуаций, начиная с того, что пока мы читали, книга из библиотеки была удалена, до того, что нет доступа к хранилищу данных. На диаграмме, все это скрыто за элементом указывающим на наличие ссылки на дополнительную диаграмму, и рассматриваться не будет, так как корректная обработка исключительных ситуаций достойна отдельного цикла статей.
В случае удачного сохранения, сигнал побуждает представление выделить процитированный участок на отображении текста. Ведь до сохранения этого делать не следует, так как может ввести в заблуждение пользователя.
Функционал создания комментариев выглядит подобным образом с единственным дополнением, вместе с границами выделения передается содержание комментария. В остальном отличий практически нет.
В последствии, на основании построенных диаграмм, можно описать набор интерфейсов, используя которые легко организовать корректное разделение функционала отвечающего за представление данных и бизнес-логику их обработки. Такой подход может значительно упростить разделение кажущего монолитным функционала на отдельные модули. Помимо этого, с помощью диаграмм последовательности легко разделяются данные и методы работы с ними.
Следующие, на что были нацелены приводимые примеры, это показать как принятие простых решений помогает решать довольно сложные задачи. Собственно говоря, все проектирование сводится к разделению сложной задачи на более простые, если и они кажутся сложными необходимо просто провести разделение еще раз. Диаграммы же помогают упорядочить цепь рассуждений и обращают внимание на не очевидные взаимосвязи.
Еще одно важное замечание, которое позволит упростить проектирование. Нет необходимости глубоко погружаться в детали, определять типы данных и алгоритмы их обработки. Детали реализации, определяют конкретные программисты, точнее, они определяются в ходе ежедневных встреч, которые в Agile называются Daily meeting. Сосредоточенность команды проектирования на конкретных инструментах всегда ухудшает качество анализа.
Автор: Юрий Е. - 2025 г.