Текущая статья завершает цикл статей по теме проектирования. Ниже описывается, пожалуй, самый трудный этап. Переход от абстрактных рассуждений к конкретной реализации в виде исходного кода. Сложность заключается, в необходимости иметь значительные знания по теории программирования и опыта разработки программного обеспечения, и эти два пункта тесно связаны между собой. Теоретические основы описывают, как и почему необходимо применять тот или иной приём проектирования, а практические навыки позволяют принимать правильные решения, снижая количество допущенных ошибок.
Настоящая статья описывает последовательность действий и разъясняет, почему были приняты те или иные решения. Однако, к сожалению, формат статьи не может вместить всё разнообразие вариантов и подходов к проектированию, и поэтому не является инструкцией. Она скорее послужит небольшим примером, для того чтобы самому попробовать разобраться в этой теме.
Перед тем как продолжить чтение, рекомендуется ознакомиться с предыдущими статьями цикла, это позволит понять последовательность принимаемых решений, так как часть из них была уже описана ранее.
Начнем со структуры модулей. Еще с первых диаграмм мы старались разделить весь проект на модули, которые, в последствии, можно проектировать отдельно. Каждый из этих модулей может и чаще всего должен стать отдельным программным пакетом, реализованным в отдельном пространстве имен или файле сборки. Это не является догмой, но правильное разделение на модули позволит в будущем, модернизировать программный продукт без необходимости перепроектирования больших объемов кодовой базы. Итак, на диаграмме модулей отражены четыре модуля.
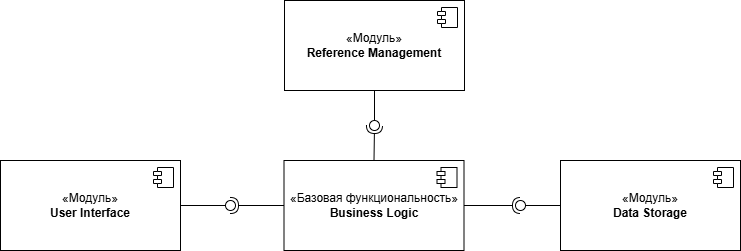
Модуль базовой функциональности, в котором реализована основная бизнес-логика приложения. Бизнес-логика являет самой стабильной частью разрабатываемого приложения, ведь для её автоматизации и создавалась. После запуска приложения в коммерческую эксплуатацию, этот модуль может меняться только после смены бизнес-стратегии, и это повлечет за собой изменение в других компонентах системы. Такую переработку функционала, скорее всего, лучше рассматривать как новую версию приложения, чем пытаться вносить изменения в уже имеющийся функционал.
Следовательно, если на этапе проектирования становится понятно, что в функционал планируется внесение изменений, лучше этот функционал выделить в отдельный модуль, даже если кажется, что он является основой приложения. Например, заказчик на этапе проектирования указывает, что форма каталога интернет-магазина может измениться в ходе продаж. Тогда лучше изначально выделить инструменты построение каталога в отдельный модуль и заложить возможность их изменения.
В нашей электронной библиотеке, таким функционалом является модуль управления ссылками. Под ссылкой понимается набор связанных данных указывающих на элементы текста, такие как ссылка на книгу, на главу в книге, на номер абзаца и другие возможные служебные данные. При этом, на момент проектирования трудно с достоверной точностью определить не только состав такой ссылки, но и методы её получения. Многое зависит от формата хранения данных. Логично предположить, что при тестировании возникает не нулевая вероятность того, что в данные будут вноситься изменения. Учитываю такую вероятность, функционал ссылки логично вынести в отдельный модуль.
Здесь следует сделать отступление и предоставить цепочку рассуждений которая привела к такому решению. Часть логики уже была озвучена в предыдущих статьях, но думаю стоит вернуться, и полностью описать последовательность решений.
Проблема отображения книг, заключается в том, что человек фокусирует свое внимание только на не большом участке. Типичным поведением является последовательное чтение, после которого следуют периоды перемещения по тексту, когда читатель возвращается к прочитанному, уточняет термины и определения, возвращается к месту чтения, обращается к оглавлению, алфавитному указателю, читает сноски и обращается внешним источникам.
С точки зрения устоявшихся терминов, читатель использует внутренние и внешние ссылки, а также поисковые теги. Следовательно приложение должно в минимальные сроки предоставлять запрошенный контент.
Как же это происходит с электронными книгами в их классическом представлении. Это файл с последовательным содержанием, поиск в котором осуществляется также последовательно, и сложность не только в поиске. Для быстрого доступа к данным, все тексты указанные в активных ссылках должны быть предварительно получены, и не важно где вы планируете это делать, у клиента, в логике или базе данных, в любом случае это выльется в значительные затраты при программировании или эксплуатации.
Отсюда следует логичный вывод, что все тексты должны быть предварительно размечены для упрощения поиска. Но это еще не все, для того чтобы не выполнять последовательный поиск по тексту логично разделить книгу на составные части и хранить каждую из них отдельно. Тогда по ссылке мы можем получить содержание только запрошенной части не тратя ресурсы на получение всего содержимого и поиск по нему.
Теперь следует определить, минимальную единицу хранения данных. Страницы, главы, части, слишком крупные для удобной работы с ними, слова и предложения слишком мелкие. Следовательно, оптимальной единицей работы с книгой является абзац. Он достаточно не велик для последовательного поиска, не занимает много места при операциях и что не мало важно, имеет прямоугольную форму для отображения в пользовательском интерфейсе.
Внимательный читатель обратит внимание, что мы не изобрели велосипед, так построены многие форматы HTML, FB2, EPUB. Это говорит лишь о том, что цепочка наших рассуждений верна.
Далее от декомпозиции нашей задачи, следует перейти к композиции. Мы определились, что будет единицей хранения текста, теперь необходимо создать такой тип ссылки который бы позволял осуществлять сложные переходы и поиск по контенту.
В первую очередь стоит отбросить идею последовательного доступа к элементам. Получение следующего абзаца путем, ссылка на текущий элемент +1, выглядит привлекательно только в рамках одного раздела книги, например главы. Во всех остальных случаях такой подход не приемлем. Все книги имеют древовидную структуру и мы будем придерживаться той же стратегии представим абзацы, как листья дерева, а главы, разделы и другое форматирование как узлы.
Таким же образом поступим и в разрезе библиотеки в целом. Каждая книга будет принадлежать к библиотечно-библиографическая классификации (ББК). Теперь мы сможем проследить ссылку от ББК до конкретного абзаца и из каждой вершины провести ребро до любого другого с помощью тегов, а далее достаточно применить теорию графов и можно с легкостью строить сложные поисковые запросы.
В будущем, можно сохранять типовые запросы для быстрого поиска, описать свой язык запросов или даже создать AI-чатбот, в рамках библиотеки. Но вернемся к проектируемой нами ссылке. С одной стороны, она должна содержать минимум информации для получения элемента данных, с другой, иметь возможность получать полный объем данных для участия в поисковых запросах.
На данный момент достаточно знать что абзац X находится в главе Y, который содержится в книге Z. Вариант ссылки типа “XYZ”, отбрасываем сразу, в случае любого изменения придется переписывать весь функционал заново. {“book”: “Z”, “chapter”: “Y”,
“paragraph”: “X”} выглядит лучше и может быть легко расширен без потери функциональности, однако все еще громоздкий. Предполагается определенная заранее структуризация, что в ситуации когда мы до конца не можем оценить глубину деревьев поиска, может привести к существенным осложнениям даже на этапе тестирования. К счастью, уже существует решение которое отвечает большинству наших требований. Это паттерн Компоновщик (англ. Composite).
На основании выбранного паттерна строится ссылка которая поддерживает необходимую нам структуру и легко расширяется путем добавления функционала. Инструменты работы с ссылкой объединяются в независимый модуль. Интерфейсы базового модуля позволят подключать новые версии модуля без внесения изменений в саму бизнес-логику.
Дальнейшее проектирование модуля работы с ссылками представляется тривиальным, необходимо лишь придерживаться правил построения паттерна. Поэтому перейдем к описанию модуля представления, точнее к методам проектирования интерфейсов подключения модулей.
Реализация пользовательского интерфейса сильно зависит от применяемого технического решения. Реализация веб-интерфейса будет сильно отличаться от интерфейса мобильного приложения, однако трехзвенная архитектура проектируемого нами программного продукта не предполагает сложных взаимосвязей. Точнее мы должны разработать проектную документацию таким образом, чтобы её можно было использовать и в мобильном и в веб решении без существенной переработки.
Для начала вернемся к написанному в предыдущих статьях. Все предыдущие этапы проектирования преследовали две цели. Первая, определить рамки проекта, то есть юридически обосновано указать заказчику, что за оговоренное возмещение мы будем выполнять оговоренный объем работ, а все остальное не входит в наши договоренности. Вторая, технически описать движение данных от их ввода до мест хранения и в обратном порядке, с указанием мест их изменения.
В предыдущей статье был расписан пример такого описания на основании диаграммы последовательности. Теперь мы сможем использовать его для описания абстракций, которые в последующем превратим в конкретные классы.
Возьмем отдельный участок диаграммы последовательности и отобразим как просто создается структура абстракций. Кратко напомню ее содержание. Диаграмма отражает последовательность движения данных при инициализации системы. Разделена на три части согласно паттерна MVC. Вне рамок диаграммы мы получаем некий идентификатор, однозначно определяющий владельца сессии. Это может быть все что угодно, результат идентификации через логин и пароль, IMEI мобильного оборудования или внутри программный ключ. Идентификатор передается в модуль бизнес-логики, где из места хранения данных извлекаются параметры для восстановления предыдущей сессии. На их основе строится интерфейс пользователя. Внутри этого процесса отправляется запрос на получение содержимого. Допустим в параметрах содержится информация о владельце, интерфейсе, предыдущей сессии и все такое. Естественно в параметрах содержится и информация о читаемой книге и закладка, а там ссылка на конспект с цитатами и комментариями. Все это мы запрашиваем пока строится интерфейс. Когда вся визуальная часть построена, мы передаем ее в представление для отображения.
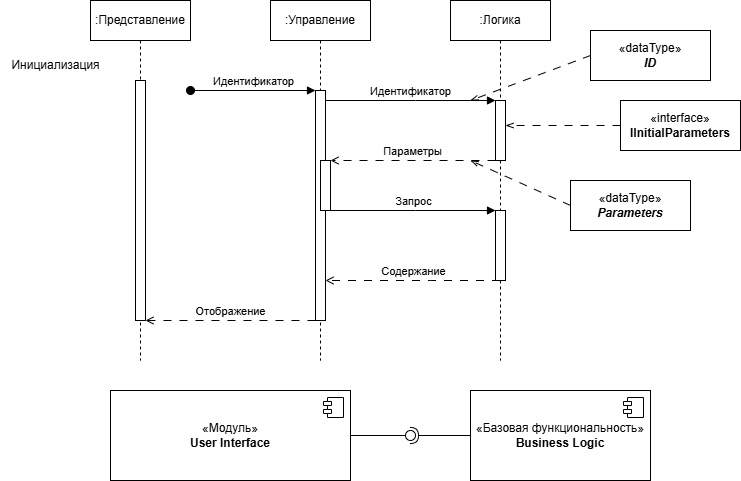
Здесь важно обратить внимание на то что мы строим абстрактную часть приложения, не погружаясь в детали. Для группы проектирования погружение в детали это проторенный путь к необоснованному усложнению программного продукта, срыву сроков, переработкам и спагетти коду. С этим многие поспорят, но личный опыт говорит именно об этом. Даже в архитектуре, где строительство связано с жизнями людей и большими денежными вложениями у строителей есть выбор действий. Можно использовать кирпич той или иной фирмы, лишь бы он соответствовал определенным параметрам.
Вот и задача группы проектирования заключается в том, чтобы определить рамки, а наполнение, будет меняться, в ходе уточнения проекта, тестирования и даже при смене программиста.
Вернемся к диаграмме. Обозначим идентификатор и набор параметров как типы данных, метод который извлекает параметры как интерфейс. Такие же операции проведем над остальными диаграммами последовательности из предыдущий статьи и получим абстрактную модель модуля базового модуля.
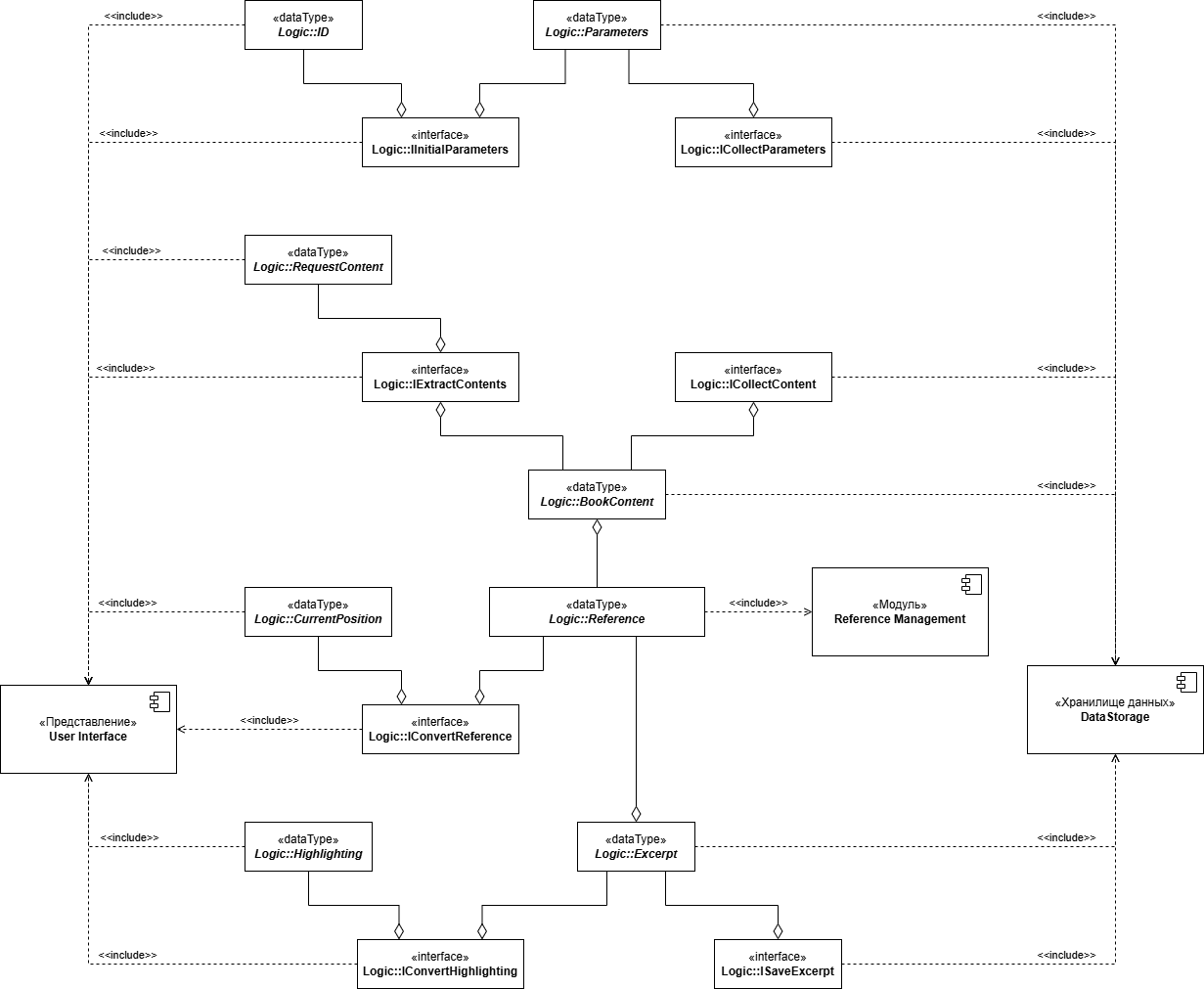
Это конечно не все описание, только та часть которая используется в качестве примера. Но она дает понимание, процесса трансформации довольно отстраненных понятий, больше связанных бизнес-процессами, чем программой. В набор абстракций на которых достаточно просто построить описание классов и их взаимодействия между собой.
Сделаю еще одно отступление, в ходе которого хотелось бы предупредить, что такие действия не выполняются так просто. Их описание в статье выглядит достаточно естественным, однако кажущаяся легкость процесса требует глубоких знаний и опыта.
Функционал был разделен из необходимости соблюдать правила модульности и декомпозиции. Разбиение системы на независимые модули позволяет обеспечить слабую связанность (англ. low coupling) между модулями и высокую связность внутри модулей (англ. high cohesion). На диаграмме легко прослеживается использование слоёв (англ. presentation, business logic, data access), или в другой терминологии трехзвенная архитектура. Абстракции это вообще универсальный инструмент, они применяются начиная от тестирования до удобства поддержки. При тестировании, абстракции это естественные входы для создания тестовых объектов (англ. mock, stub). Удобство поддержки обеспечивается тем, что на основании абстракций можно строить новые версии функционала не прибегая к его глубокой перестройке (англ. Refactoring). Следует включить еще Design Pattern, SOLID, DRY, KISS, YAGNI и многое другое.
К сожалению, недостаточно обладать этими теоретическими знаниями, необходимо написать тысячи строк кода, выкинуть их и написать снова, проанализировать и понять, что если бы здесь и здесь использовал то и то было бы все проще, а иногда просто закрыть глаза на все эти умные аббревиатуры и делать так как подсказывает логика.
Вернемся к нашей диаграмме, рассмотрим левую часть и организуем взаимодействие модулей. Как написано выше, модуль базового функционала является основным по отношению к другим. Вероятность изменения бизнес-процессов намного меньше чем вероятность изменения интерфейса. Именно по этому выбран такой приоритет. Следовательно, базовый должен иметь абстракции с помощью которых подключаются другие.
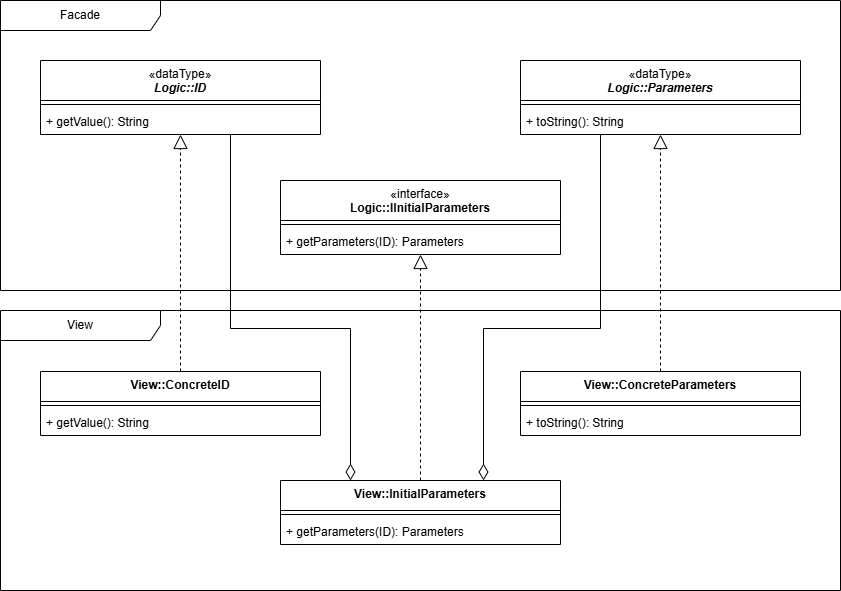
На диаграмме смоделировано такое подключение, только одного интерфейса предназначенного для получения начальных параметров.
Две абстракции представляют типы данных и одна описывает интерфейс. Вместе они представляют паттерн Фасад (англ. Facade). Хотя в классическом описании фасад представляется единым классом, в реальности есть две крайности, когда отдельные методы объединяют в единый интерфейс, чтобы строго соответствовать паттерну, и второй когда каждая абстракция представляется отдельным фасадом. Как и все крайние случаи они имеют существенные недостатки, следовательно лучше искать что-то среднее.
Еще один совет заключается в том, что не надо смешивать данные и методы. К сожалению нас так учат, и от этого сложно избавиться. Поэтому приведу пример часто используемый при обучении. Здесь и далее все примеры приведены на языке Java.
public class Main { public static void main(String[] args) { MyTime time = new MyTime(); System.out.println(time.getHour() + ":" + time.getMinute()); }}
public class MyTime { private LocalTime _time; public MyTime() { _time = LocalTime.now(); } public int getHour() { return _time.getHour(); } public int getMinute() { return _time.getMinute(); }}
Классический обучающий пример для практики работы с геттерами, и он действительно очень хорош на первых этапах. Однако в реальных проектах типы данных имеют сложную структуру и часто изменяют свою форму преследуя различные цели, поэтому объединение в одном классе данных и методов их обработки не только нарушает принцип единственной ответственности (англ. Single Responsibility Principle, SOLID), но и запутывает код. Создавая те самые спагетти.
Теперь рассмотрим тот же пример но с разделением данных и методов их обработки.
public class Main { public static void main(String[] args) { MyLocalTime localTime = new MyLocalTime(); ConvertTime converter = new ConvertTime(); MyInnerTime innerTime = converter.convert(localTime); System.out.println(innerTime); }}
public class MyLocalTime { private LocalTime _time; public MyLocalTime() { _time = LocalTime.now(); } public LocalTime get() { return _time; }}
public class MyInnerTime { private int _hour; private int _minute; public MyInnerTime(int hour, int minute) { _hour = hour; _minute = minute; } @Override public String toString() { return _hour + ":" + _minute; }}
public class ConvertTime { public MyInnerTime convert(MyLocalTime local) { return new MyInnerTime(local.get().getHour(), local.get().getMinute()); }}
Классов стало больше, это стандартный недостаток соблюдения всех правил программирования, но классы стали меньше, проще и ни один из классов не знает о другом. Такой подход дает возможность легко модифицировать программный код, особенно если все это построить на абстракциях. Так мы распутываем те самые спагетти еще на этапе проектирования. К сожалению это не все подводные камни которые можно описать на этом примере, формат статьи ограничивает, поэтому вернемся к тому на чем остановились.
На диаграмме однозначно выделено, что абстракции относятся к модулю базового функционала, а конкретные классы созданные на их основе к модулю представления.
Давайте сейчас рассмотрим примерный исходный код, а далее опишем как все это может работать в реально проекте.
//package com.example.project.main;public class Main { public static void main(String[] args) { // Создаем реальные объекты для абстракций ID id = new ConcreteID("Test"); InitialParameters initial = new InitialParameters(); // Оперируем только абстракциями Parameters param = initial.getParameters(id); System.out.println(param); }}
//package com.example.project.logic;public abstract class ID {}public abstract class Parameters {}interface IInitialParameters { Parameters getParameters(ID id); }
//package com.example.project.view;public class ConcreteID extends ID { private String _id; public ConcreteID(String id) { _id = id; } String getValue() { return _id; }}
public class ConcreteParameters extends Parameters { private String _value; public ConcreteParameters(String value) { _value = value; } @Override public String toString() { return _value + " parameters"; }}
public class InitialParameters implements IInitialParameters { public Parameters getParameters(ID id) { return new ConcreteParameters(((ConcreteID)id).getValue()); }}
Возьмем некую близкую к идеальной среду, содержание пакета контролирует отдельный программист или их группа. Исходный код под контролем системы управления версиями и используя абстракции мы создали набор модульных тестов для контроля над качеством.
Мы используем гибкий подход к управлению проектами (англ. Agile), следовательно можем получить задание внести изменения в модуль представления. Неважно в какой момент это происходит, на этапе разработки, внедрения или поддержки. Вот тут мы начинаем получать преимущества, которые были заложены при проектировании.
Копируем исходный код пакета в новую ветвь (англ. branch если это git) и вносим необходимые нам изменения, если требуется изменение внутренней структуры пакета (англ. Refactoring), просто создаем его заново на имеющихся абстракциях. Проходим тесты, и по окончании проекта удаляем не актуальных ветви.
Далее рассмотрим два важных аспекта, как определить оптимальный размер модуля, и необходимо ли использовать абстракции внутри него.
Теоретические определения скрывающиеся за различными аббревиатурами не отражают реальной жизни и по этому часто кажутся неисполнимыми и не отражающих актуальных требований. Все это происходит из-за влияния человеческого фактора.
Если ваша команда состоит исключительно из опытных разработчиков, то в отдельной группе отвечающей за проектирование нет необходимости. Высококлассные специалисты всегда выработают приемлемое решение. Программистам с низкой квалификацией не поможет и диаграмма классов, которая детализируется до наименований параметров и методов каждого класса. Следовательно, выполнять декомпозицию модулей необходимо до уровня компетенции разработчиков.
Исходный код модуля проходящего все тесты самодостаточен, даже если он является образцом спагетти кода. Необходимо помнить, проектирование экономит ресурсы за счет, снижения затрат, и обеспечения управляемости проекта. Именно по этой причине, участники такой группы должны позиционировать себя ближе к управлению проектами, чем программированию.
Внутренний девиз проектировщиков должен сводится к идее, что чем опытнее команда разработчиков, тем крупнее модули, а значит, мне меньше работы. Команда проектировки может отслеживать и анализировать совершаемые ошибки. На их основе создавать и корректировать программу внутреннего обучения.
Однако существуют ситуации, когда уменьшать размер модуля не целесообразно, а вероятность внесения изменений достаточно высока. В таких случаях целесообразно погрузиться в его функционал и перед началом разработки предусмотреть возможность модификации.
В качестве примера, рассмотрим реализацию модуля отвечающего за хранение данных. Выполнять его дальнейшую декомпозицию, в нашем случае, не целесообразно, так как какую бы систему хранения данных не выбрали, она может меняться. Выход новой версии системы хранения, появление нового функционала, вопросы производительности по ходу эксплуатации и развития программного продукта. Все это может потребовать значительной переработки, а следовательно полной замены исходного кода, но возможны и случаи когда необходимо подправить отдельные команды в целях оптимизации хранения или производительности.
В таких случаях необходимо опуститься на уровень модуля и ввести некоторые ограничения на внутреннюю структуру модуля. В нашем примере необходимо добавить еще две абстракции, одна из которых отвечает за особенности подключения к хранилищу данных, а вторая за возможность добавления новых команд.
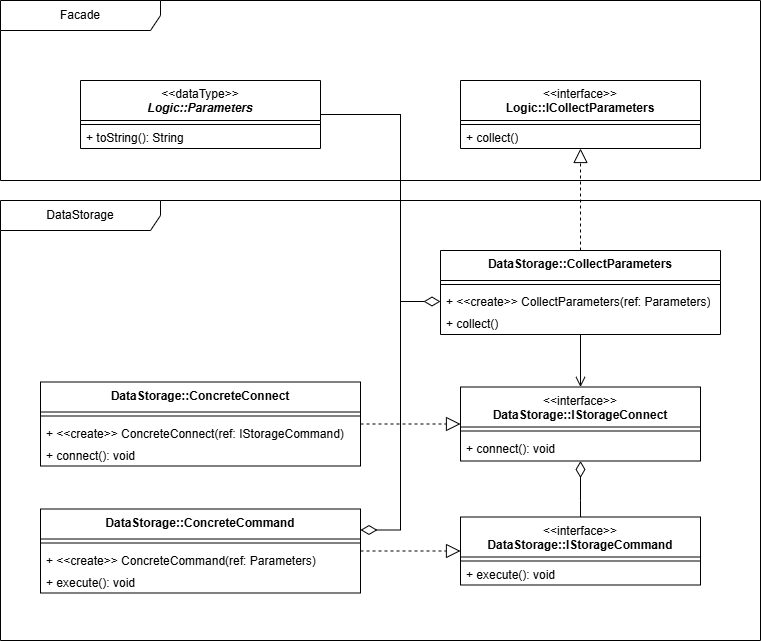
Обе абстракции реализуют возможность расширения с использованием паттерна Фабричный метод (англ. Factory Method). На основании интерфейса IStorageConnect создается класс обеспечивающий управление подключением к источнику данных. При изменении формата подключения просто создаем еще один класс учитывающий новые особенности, а поскольку все взаимодействие построено на основании интерфейса появляется возможность обойтись без значительной переработки исходного кода.
Для тех же целей добавлен второй интерфейс. Он обеспечивает необходимую гибкость при внесении изменений и создания новых команд для взаимодействия с источником данных.
//package com.example.project.main;public class Main { public static void main(String[] args) { Parameters param = new ConcreteParameters(); ICollectParameters collecting = new CollectParameters(param); collecting.collect(); System.out.println(param); }}
//package com.example.project.logic;public abstract class Parameters {}interface ICollectParameters { void collect(); }
//package com.example.project.datastorage;interface IStorageConnect extends AutoCloseable { void connect(); }interface IStorageCommand { void execute(); }
public class ConcreteParameters extends Parameters { protected String first; protected Integer second; protected Double third; @Override public String toString() { return "" + first + ", " + second + ", " + third + ", parameters"; }}
public class FirstCommand implements IStorageCommand { private ConcreteParameters _parameters; public FirstCommand(Parameters parameters) { _parameters = (ConcreteParameters)parameters; } public void execute() { _parameters.first = "first"; _parameters.second = 10; _parameters.third = 12.345; }}
public class ConcreteConnect implements IStorageConnect { private IStorageCommand _command; public ConcreteConnect(IStorageCommand command) { _command = command; System.out.println("connect"); } public void connect() { _command.execute(); } @Override public void close() { System.out.println("disconnect"); }}
public class CollectParameters implements ICollectParameters { private Parameters _parameters; public CollectParameters(Parameters parameters) { _parameters = parameters; } public void collect() { IStorageCommand command = new FirstCommand(_parameters); try (ConcreteConnect connection = new ConcreteConnect(command)) { connection.connect(); } }}
Подводя итоги текущей статьи и всего цикла хотелось бы напомнить основные цели и возможности связанные с проектированием. Описанные в этих статьях приемы создания проектной документацией в виде UML схем только на сорок процентов предназначены для принятия технических решений. Основная же часть работ по проектированию связана с управлением проектами.
Основной не технической целью проектирования является предоставление менеджеру проекта инструментов управления проектом и оснований для взаимодействия с заказчиком. Раньше для этих целей использовалось классическое техническое задание, однако с внедрением пошаговых, циклических методов управления проектами, актуальность его применения снизилась. Но необходимость в документации способной описать рамки проекта не отпала.
Для взаимодействия с заказчиками необходим юридически значимый набор документов описывающий технические особенности проекта. Простыми словами, необходимо документально описать, что в рамках проекта программа будет делать, например, вести учет заявок, а не отвечать на них, и тем более не запускать спутники. Проектирование на основании UML диаграмм, в графическом виде, в доступной для понимания обоим сторонам договора форме, разъясняет детали проекта и описывает его ограничения.
Диаграммы оформленные должным способом могут стать дополнением к договору или влиять на проект иным доступным по закону способом. Менеджер проекта получает согласованный с двух сторон инструмент для принятия решений.
С технической точки зрения, проектирование позволяет более равномерно распределить объём работ связанных с написанием кода, тем самым повышая его качество. Решения принятые группой проектирования на первом этапе, могут быть переосмыслены без больших затрат на переработку. В целом, программный продукт получается более гибким и адаптированным к пост проектной эксплуатации.
Завершая цикл, несколько советов.
- Проект это не универсальное средство для решения всех проблем, иногда проектирование только тратит ваше время и ресурсы. Максимальная отдача от проектирования видна, когда разработка ведется под заказ или на привлеченные средства. В таких случаях, управление проектом выходит на первое место и проект играет в этом не последнюю роль.
- Проектная документация это в первую очередь инструмент управления проектом и только во вторую, описание технического решения, поэтому не следует из нее делать эталон построения приложения. Разработка программ состоит из множества принимаемых решений и на каждом этапе любой из участников проекта может принять спорное решение. Начиная от заказчика и до специалиста по тестированию. Проект призван минимизировать риск принятия спорных решений.
- Отложите принятие решения об использовании технических инструментов на конец этапа проектирования. Вполне может оказаться, что другой готовый набор инструментов (англ. framework), язык программирования или аппаратное ПО, покрывает больше потребностей, уменьшая объем кодирования.
- Оставляйте свободу в принятии решений на уровне детализации. Чистый код это не самоцель, будет отлично, если весь код написан в соответствии со всеми правилами, но сроки исполнения важнее. Задача группы проектирования следить за детализацией узловых точек, уровнем разделения на модули и обеспечить корректное их взаимодействие.
Автор: Юрий Е. - 2025 г.